
Database Management System (DBMS)
Introduction :
In the dynamic landscape of information technology, where data has become the lifeblood of organizations, the role of Database Management Systems (DBMS) has emerged as indispensable. A Database Management System is a software application that interacts with the user, applications, and the database itself to capture and analyze data efficiently. Its significance lies in providing a structured and organized approach to store, manage, and retrieve vast amounts of data in a secure and scalable manner.
Key Components and Architecture:
A typical DBMS comprises several key components, including the database itself, the DBMS software, users, and the application programs that interact with the database. The architecture of a DBMS is designed to facilitate seamless data management. The three-tier architecture, consisting of the user interface, business logic, and database server, ensures a clear separation of concerns, enhancing maintenance and scalability.
Data Models:
DBMS supports various data models, each catering to specific requirements. The relational model, based on tables with rows and columns, is widely used for its simplicity and flexibility. Other models include hierarchical and network models, but the relational model has gained prominence due to its effectiveness in handling complex relationships between data entities.
Data Integrity and Security:
Maintaining data integrity is a critical aspect of DBMS. It ensures accuracy and consistency in the stored data, preventing anomalies that may arise during data manipulation. Security features are embedded within DBMS to safeguard against unauthorized access, data breaches, and ensure compliance with privacy regulations. Access controls, encryption, and authentication mechanisms contribute to a robust security framework.
Query Language:
Structured Query Language (SQL) is the standard language for interacting with relational databases. SQL allows users to define, manipulate, and control the data within a database. Its versatility in performing tasks such as querying, updating, and managing schema makes it an essential tool for database professionals.
Scalability and Performance:
DBMS plays a pivotal role in ensuring scalability and optimal performance as data volumes grow. Through techniques like indexing, query optimization, and efficient storage mechanisms, DBMS enables organizations to handle large datasets without sacrificing performance. Scalability is crucial in adapting to the evolving needs of businesses in today’s dynamic environment.
Data Recovery and Backup:
The robustness of a DBMS is evident in its ability to recover from failures and ensure data durability. Regular backup mechanisms and transaction logging provide safeguards against data loss due to hardware failures, system crashes, or other unforeseen events. These features contribute to the reliability and availability of data, a cornerstone for business continuity.
Distributed Databases:
As organizations expand globally, the need for distributed databases has surged. DBMS facilitates the creation and management of distributed databases, allowing data to be stored and processed across multiple locations. This ensures real-time access to information, collaboration, and improved responsiveness to changing business conditions.
Evolution and Trends:
DBMS has undergone significant evolution over the years, adapting to technological advancements. The rise of cloud computing has introduced Database as a Service (DBaaS), offering flexible and scalable database solutions without the need for physical infrastructure. Additionally, NoSQL databases have gained traction for their ability to handle unstructured and semi-structured data, providing alternatives to traditional relational databases.
In conclusion, Database Management Systems play a pivotal role in modern information systems, serving as the backbone for data-driven decision-making. The efficiency, security, and scalability offered by DBMS make it an indispensable tool for organizations navigating the complex landscape of data management in the digital age. As technology continues to advance, the role of DBMS will likely evolve, shaping the future of data storage and retrieval.
Purpose of Database System :
Unveiling the Foundation of Data Management :
A Database System is a crucial element in the realm of information technology, serving a multifaceted purpose that extends far beyond mere data storage. Its primary objectives revolve around organizing, managing, and facilitating efficient access to vast amounts of data. Understanding the purpose of a Database System is essential for appreciating its significance in modern business, scientific research, and virtually every domain where data plays a pivotal role.
1. Data Organization and Structuring:At the core of a Database System’s purpose lies the need to organize data in a structured manner. Instead of storing information in disparate files or spreadsheets, a Database System employs a systematic approach, typically using tables and relationships. This structured organization enhances data integrity, reduces redundancy, and provides a coherent framework for data representation.
2. Data Retrieval and Accessibility:One of the primary goals of a Database System is to enable efficient data retrieval. Users, applications, and systems interact with the database to query and retrieve specific information. The use of Structured Query Language (SQL) facilitates this interaction, allowing users to perform complex queries, filter data, and extract meaningful insights from the stored information.
3. Data Integrity and Consistency:Ensuring the accuracy and consistency of data is paramount. Database Systems implement mechanisms to enforce data integrity constraints, preventing inconsistencies and errors. These constraints include unique keys, foreign key relationships, and validation rules that maintain the quality and reliability of the stored information.
4. Data Security and Access Control:Database Systems play a crucial role in safeguarding sensitive information. Security features, such as authentication, authorization, and encryption, are integral components. Access control mechanisms restrict unauthorized users from accessing or modifying data, protecting the confidentiality and privacy of critical business information.
5. Support for Concurrent Access:In a dynamic environment where multiple users and applications interact with the database simultaneously, Database Systems provide mechanisms for concurrent access. Through transaction management and locking mechanisms, DBMS ensures that multiple transactions can be processed concurrently without compromising data consistency.
6. Data Redundancy Elimination:Efficient use of storage is a key objective of a Database System. Redundancy, where the same data is stored in multiple locations, is minimized through normalization techniques. By breaking down data into smaller, interrelated tables, redundancy is reduced, leading to optimal storage utilization and streamlined maintenance.
7. Scalability and Performance Optimization:The scalability of a Database System is crucial to accommodate growing volumes of data and user demands. Database administrators employ optimization techniques such as indexing, query optimization, and caching to enhance performance. Scalability ensures that the system remains responsive and efficient as data requirements expand.
8. Data Recovery and Backup:Database Systems prioritize data durability by implementing robust recovery mechanisms. Regular backups, transaction logs, and checkpoints enable organizations to recover from system failures, hardware malfunctions, or other unforeseen events. These features contribute to the resilience and reliability of the database system.
9. Support for Business Logic and Applications:Database Systems serve as a foundation for business applications by supporting the implementation of business logic. Integration with application programming interfaces (APIs) and the ability to execute stored procedures allow for the encapsulation of complex business rules within the database, promoting consistency and maintainability.
10. Facilitating Decision Support and Reporting:Business intelligence and decision-making rely heavily on the ability to analyze and report on data. Database Systems support the extraction and transformation of data for reporting purposes. This facilitates informed decision-making by providing timely and accurate insights into organizational performance.
In essence, the purpose of a Database System extends far beyond mere data storage—it is an intricate ecosystem designed to facilitate effective data management, ensure data quality, and empower organizations to harness the full potential of their information assets. As technology continues to evolve, the role and capabilities of Database Systems will likely expand, reinforcing their pivotal position in the landscape of information management.
Levels of Abstraction :
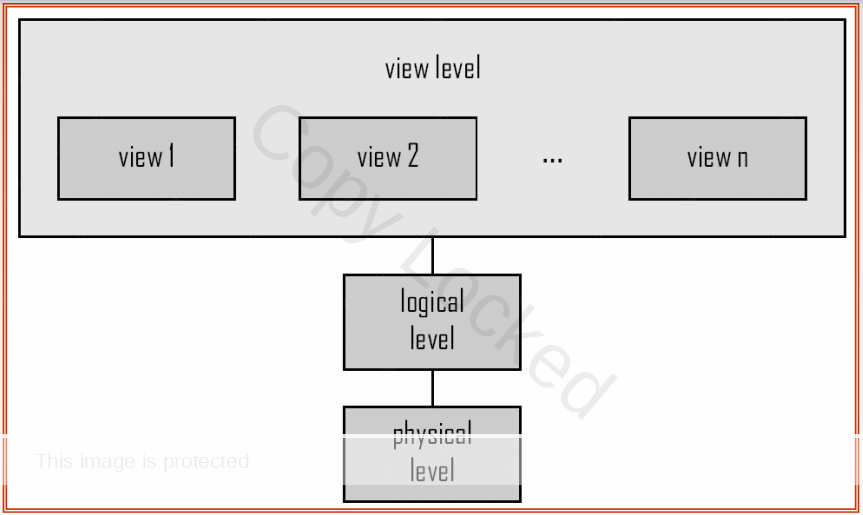
The Three-Level Architecture, also known as the three-schema architecture, is a foundational concept in Database Management Systems (DBMS) that aims to provide a clear and organized separation of concerns in the design and implementation of databases. This architectural model comprises three distinct levels: the View Level, Logical Level, and Physical Level. Each level serves a unique purpose, contributing to the overall efficiency, manageability, and adaptability of the database system.
1. View Level (External Schema):The View Level, also referred to as the External Schema, represents the user interface to the database. It is the outermost layer that interacts directly with end-users, application programs, and various user interfaces. At this level, the focus is on presenting a customized and simplified view of the data, tailored to the specific needs and requirements of different user groups.
Multiple views can exist at the View Level, each encapsulating a subset of the database’s data and presenting it in a way that is meaningful for a particular user or application. The View Level shields users from the complexities of the underlying data structures and allows for a more intuitive and user-friendly interaction with the database.
2. Logical Level (Conceptual Schema):Sitting between the View Level and the Physical Level, the Logical Level, also known as the Conceptual Schema, defines the overall structure and organization of the entire database. It provides an abstract representation of the data model, emphasizing the relationships and constraints between different entities and their attributes.
At the Logical Level, the emphasis is on data independence, separating the way data is viewed and manipulated from the physical storage details. The conceptual schema is typically described using a high-level data model, such as the entity-relationship model or the relational model. This level abstracts away the complexities of implementation, allowing for easier modification and adaptation of the database design without affecting the external views.
3. Physical Level (Internal Schema):The Physical Level, also referred to as the Internal Schema, deals with the actual storage and retrieval of data on the physical storage devices. This level addresses the details of how data is stored, indexed, and retrieved efficiently to meet performance requirements. It involves decisions related to data storage structures, access paths, indexing mechanisms, and optimization strategies.
Database administrators and system architects work at the Physical Level to ensure that the database system operates efficiently and meets performance expectations. This level is concerned with aspects such as disk storage, file organization, and indexing techniques. Changes at the Physical Level should ideally be transparent to both the Logical Level and the View Level, preserving data independence.
Benefits of Three-Level Architecture:The Three-Level Architecture provides several advantages in the design and management of database systems:
- Data Independence: The separation of levels ensures that changes at one level do not impact the others, promoting data independence. This means modifications to the physical storage structure won’t affect the logical or view levels, and vice versa.
- Enhanced Security and Access Control: The View Level allows for the implementation of access controls, restricting users to specific views of the data. This ensures that sensitive information is only accessible to authorized users.
- Improved Maintenance and Adaptability: Changes to the database structure can be made at the Logical Level without affecting external views. This flexibility simplifies maintenance tasks and allows for the adaptation of the database to evolving business requirements.
- Facilitates Multiuser Environments: The Three-Level Architecture is well-suited for multiuser environments where different users or applications may have diverse data requirements. It allows for the creation of customized views without compromising the overall database structure.
In conclusion, the Three-Level Architecture provides a comprehensive framework for designing and managing complex database systems. By delineating the user interface, logical structure, and physical implementation, this architectural model promotes clarity, adaptability, and efficiency in the realm of database management.
Instances and Schemas
Instances and Schema in Database Management Systems (DBMS): Navigating Data Representation
In the realm of Database Management Systems (DBMS), instances and schema play pivotal roles in structuring and organizing data. They provide a framework for understanding the data model, defining the structure of the database, and capturing the dynamic nature of information. Let’s delve into the concepts of instances and schema to unravel their significance in the world of data management.
1. Database Schema:
A database schema is a blueprint or a logical framework that defines the structure of a database. It encompasses the organization of data into tables, the relationships between these tables, constraints, and other relevant information. The schema provides a high-level, abstract view of how data is organized without specifying the actual data values.
There are two main types of schemas:
Logical Schema (Conceptual Schema): This defines the organization of data conceptually, emphasizing the relationships between different entities. It serves as a high-level representation of the entire database structure, independent of the physical storage details.
Physical Schema (Internal Schema): This deals with the physical storage and retrieval of data, specifying how data is stored on the disk, access paths, and indexing structures. The physical schema is concerned with optimizing performance and storage efficiency.
The database schema acts as a foundation for creating instances, ensuring consistency and integrity in the way data is stored and retrieved.
2. Database Instance:
A database instance is a snapshot or a specific occurrence of a database at a given moment in time. It represents the actual data stored in the database, including the values, records, and relationships between entities. In essence, an instance provides a real-time view of the data within the defined schema.
For example, consider a database schema that defines a table for ‘Employees’ with attributes like ‘EmployeeID,’ ‘Name,’ and ‘Department.’ A specific instance of this schema would contain the actual data, such as records for individual employees with unique IDs, names, and assigned departments.
Key Distinctions:
Static vs. Dynamic Nature:
- The database schema is relatively static, representing the overall structure and organization of the database.
- Database instances, on the other hand, are dynamic and can change as data is added, modified, or deleted.
Design vs. Content:
- Schema focuses on the design and structure of the database, providing a blueprint for data organization.
- Instances encapsulate the actual content of the database, reflecting the current state of the stored data.
Abstraction Levels:
- Schema operates at an abstraction level that defines the logical and physical organization of data.
- Instances operate at a lower level, representing the concrete data values within the defined schema.
Interplay between Schema and Instances:
The relationship between schema and instances is analogous to a class and an object in object-oriented programming. The schema serves as a template or a class definition, outlining the structure, while instances are the instantiated objects, representing the actual data conforming to that structure.
In summary, schema and instances are integral concepts in DBMS, working hand in hand to provide a comprehensive framework for data management. The schema establishes the rules and structure, guiding the creation and modification of instances that encapsulate the real-world data within the database. This interplay ensures consistency, integrity, and adaptability in the ever-evolving landscape of information storage and retrieval.
Data Models in DBMS
Data Models in Database Management Systems (DBMS): Blueprinting Information Structures
In the realm of Database Management Systems (DBMS), data models serve as conceptual frameworks for organizing, representing, and interacting with data. These models provide a structured abstraction that facilitates the understanding and manipulation of complex datasets. Here, we explore the main types of data models in DBMS and their roles in shaping the landscape of information storage and retrieval.
1. Hierarchical Data Model:
The Hierarchical Data Model represents data in a tree-like structure, organized hierarchically. Each data element has a parent-child relationship, forming a parent hierarchy. This model is intuitive and mirrors real-world hierarchical relationships. However, it can become complex when dealing with many-to-many relationships and lacks the flexibility of other models.
2. Network Data Model:
The Network Data Model builds upon the hierarchical model by allowing each record to have multiple parent and child records, forming a network of interconnected nodes. This model addresses some of the limitations of the hierarchical model, providing more flexibility in representing complex relationships. It introduced concepts like sets and pointers to navigate through the interconnected data.
3. Relational Data Model:
The Relational Data Model, arguably the most widely used, represents data as tables with rows and columns. Tables are related based on common attributes, establishing links between them. This model offers simplicity, data integrity through normalization, and supports powerful querying through Structured Query Language (SQL). The relational model is the foundation for relational database management systems (RDBMS), such as MySQL, PostgreSQL, and Oracle.
4. Entity-Relationship (ER) Data Model:
The Entity-Relationship Data Model focuses on entities and their relationships in a conceptual manner. It uses entities to represent real-world objects and relationships to illustrate connections between these entities. Attributes describe the properties of entities. ER diagrams provide a visual representation of the model, aiding in the design and understanding of complex databases.
5. Object-Oriented Data Model:
The Object-Oriented Data Model extends the concepts of object-oriented programming to databases. It represents data as objects, encapsulating data and behavior within a single unit. This model is particularly suitable for applications with complex data structures and relationships. Object-oriented databases (OODBMS) leverage this model to provide persistence for object-oriented programming languages.
6. Object-Relational Data Model:
Combining elements of both the relational and object-oriented models, the Object-Relational Data Model integrates the simplicity of relational databases with the flexibility of object-oriented databases. It supports complex data types, methods, and inheritance while maintaining compatibility with SQL queries.
7. NoSQL Data Models:
NoSQL databases, standing for “Not Only SQL,” encompass a variety of data models, deviating from the traditional relational model. Examples include document stores, key-value stores, column-family stores, and graph databases. These models are designed to handle diverse data types and offer horizontal scalability, making them suitable for large-scale, distributed systems.
8. XML and JSON Data Models:
XML (eXtensible Markup Language) and JSON (JavaScript Object Notation) are data models used for semi-structured and hierarchical data. They provide a flexible way to represent data with nested structures. XML is widely used for document storage and exchange, while JSON is prevalent in web development due to its simplicity and ease of use.
Importance of Data Models:
Conceptual Clarity: Data models provide a clear and concise representation of the structure and relationships within a database, enhancing conceptual understanding.
Consistency: By enforcing rules for data representation, models ensure consistency in how data is stored, avoiding redundancy and maintaining data integrity.
Query and Manipulation: Different data models offer varying levels of support for querying and manipulating data. A well-chosen data model can significantly impact the ease and efficiency of these operations.
Scalability and Flexibility: Some data models are better suited for specific scalability requirements or data types. The choice of a data model can influence the system’s adaptability to changing needs.
In conclusion, data models in DBMS serve as indispensable tools for designing, understanding, and interacting with databases. The selection of an appropriate data model depends on the nature of the data, the complexity of relationships, and the specific requirements of the application or system. As technology evolves, new data models continue to emerge, offering innovative solutions to address the evolving landscape of data management.
Structured Query Language (SQL) Categories :
Structured Query Language (SQL) is a powerful language used for managing relational databases. SQL can be categorized into several language categories, each serving specific purposes in the realm of database operations.
1. Data Query Language (DQL):
- Purpose: Focuses on retrieving information from the database.
- Key Command: SELECT
- Role: Enables users to specify the columns they want to retrieve, filter results based on conditions, and join multiple tables for comprehensive data retrieval.
2. Data Definition Language (DDL):
- Purpose: Deals with the structure of the database.
- Key Commands: CREATE, ALTER, DROP
- Role: Allows users to define, modify, or delete database objects such as tables, indexes, and views.
3. Data Manipulation Language (DML):
- Purpose: Encompasses commands for manipulating data within the database.
- Key Commands: INSERT, UPDATE, DELETE
- Role: Facilitates the dynamic and interactive handling of data, enabling users to add, modify, or remove records as needed.
4. Data Control Language (DCL):
- Purpose: Concerned with permissions and access control within a database.
- Key Commands: GRANT, REVOKE
- Role: Allows administrators to grant or revoke privileges, ensuring that users have appropriate access rights.
5. Transaction Control Language (TCL):
- Purpose: Manages transactions within a database.
- Key Commands: COMMIT, ROLLBACK, SAVEPOINT
- Role: Controls the initiation, completion, or rollback of transactions, ensuring data consistency and integrity.
Understanding these language categories empowers users to interact with databases comprehensively. Whether defining the structure, manipulating data, controlling access, or managing transactions, SQL’s diverse language categories provide the tools needed to navigate the complex landscape of database management.
Procedural vs Non-procedural (Declarative)
Procedural and Non-Procedural (Declarative) Classes of SQL: A Dichotomy in Database Querying
In the realm of SQL (Structured Query Language), two overarching classes define how users interact with and instruct databases: Procedural and Non-Procedural (Declarative). Each class adheres to distinct philosophies regarding how operations are specified, offering varying levels of control and abstraction.
1. Procedural SQL:
Nature:
- Imperative Approach: Procedural SQL follows an imperative approach where users explicitly outline the sequence of steps or operations to achieve a specific outcome.
- User-Defined Procedures: Central to procedural SQL is the definition of user-created procedures or routines, outlining the exact steps to be executed.
Characteristics:
- Control Over Execution: Users have explicit control over the flow and execution of operations, providing a detailed roadmap for the database engine to follow.
- Readability and Explicitness: Offers a clear, step-by-step representation, making it more explicit and readable for users familiar with programming logic.
2. Non-Procedural (Declarative) SQL:
Nature:
- Declarative Approach: Non-Procedural SQL takes a declarative approach where users specify the desired outcome without explicitly detailing the steps or sequence of operations.
- SQL Query Language: The standard SQL query language, especially the SELECT statement, is a prime example of a declarative approach.
Characteristics:
- Outcome-Centric: Users focus on what they want to achieve rather than specifying how it should be done, allowing the database engine to determine the most efficient execution plan.
- Abstraction and Simplification: Offers a higher level of abstraction, abstracting away the intricacies of implementation for simpler interaction.
Considerations:
Flexibility and Control:
- Procedural SQL: Provides more explicit control over the execution sequence, offering flexibility in defining intricate processes.
- Non-Procedural SQL: Prioritizes simplicity and abstractness, providing less control but enhancing ease of use.
Optimization:
- Procedural SQL: Requires users to consider optimization, leveraging explicit control over the process.
- Non-Procedural SQL: Relies on the database engine to optimize queries, balancing ease of use with performance considerations.
Readability and Ease of Use:
- Procedural SQL: Can be more readable for users who are accustomed to imperative programming logic.
- Non-Procedural SQL: Offers a concise and abstract representation, simplifying interactions for users focused on the desired outcome.
Choosing between Procedural and Non-Procedural SQL often depends on the specific requirements of a task and the preferences or expertise of the users involved. Procedural SQL suits scenarios where explicit control is necessary, while Non-Procedural SQL provides a more abstract and declarative approach, balancing simplicity with operational efficiency.
Database Architecture :
Database architecture refers to the structured design and organization of components within a database system, determining how data is stored, accessed, and managed. A well-designed database architecture is crucial for achieving optimal performance, scalability, and maintainability. Let’s explore the key aspects of database architecture:
1. Components of Database Architecture:
**1.1 Data Storage:
- Tables: Data is organized into tables, where each table represents a specific entity (e.g., customers, products).
- Rows (Tuples): Each row in a table represents an individual record, with each column storing a specific attribute of the record.
- Indexes: Enhance data retrieval speed by providing quick access to specific rows based on indexed columns.
**1.2 Database Management System (DBMS):
- Core Engine: Manages data storage, retrieval, and modification. Examples include MySQL, PostgreSQL, and Oracle.
- Query Processor: Translates SQL queries into executable plans for data retrieval or modification.
- Transaction Manager: Ensures the consistency and integrity of data during transactions.
**1.3 Database Access and Interface:
- SQL (Structured Query Language): Standardized language for interacting with relational databases.
- Application Programming Interface (API): Allows applications to communicate with the database using programming languages like Java, Python, or C#.
2. Database Models:
**2.1 Relational Model:
- Organizes data into tables with rows and columns.
- Enforces relationships between tables using keys (primary and foreign keys).
- Provides a structured and mathematical approach to data representation.
**2.2 NoSQL Models:
- Document Store, Key-Value Store, Graph Database, and Columnar Store are examples of NoSQL models.
- Suited for specific use cases where flexibility and scalability are prioritized over rigid relational structures.
3. Database Architecture Patterns:
**3.1 Client-Server Architecture:
- Two-tier architecture with a client-side application and a server-side database.
- Suitable for smaller applications with straightforward communication between the client and the database server.
**3.2 Three-Tier Architecture:
- Presentation layer, application layer, and data layer are distinct.
- Enhances modularity, scalability, and security by separating concerns.
**3.3 Microservices Architecture:
- Organizes applications as a collection of loosely coupled, independently deployable services.
- Each microservice may have its database, enabling flexibility and scalability.
4. Database Security:
**4.1 Authentication and Authorization:
- Ensures that only authorized users access the database.
- Authentication verifies user identity, while authorization defines user permissions.
**4.2 Encryption:
- Protects sensitive data during transmission and storage using encryption algorithms.
- Ensures data confidentiality and integrity.
5. Data Integrity and Consistency:
**5.1 Constraints:
- Enforced rules, such as primary key constraints, foreign key constraints, and unique constraints, to maintain data integrity.
- Prevents data anomalies and inconsistencies.
**5.2 Transactions:
- Groups database operations into atomic units to ensure consistency and integrity.
- Follows the ACID properties (Atomicity, Consistency, Isolation, Durability).
6. Scalability:
**6.1 Horizontal Scaling:
- Distributes data across multiple servers to handle increased load.
- Commonly used in NoSQL databases.
**6.2 Vertical Scaling:
- Increases the capacity of a single server by adding more resources (CPU, RAM).
- Common in traditional relational databases.
7. Data Replication and Sharding:
**7.1 Replication:
- Copies data to multiple locations to improve fault tolerance and availability.
- Can be used for read scalability.
**7.2 Sharding:
- Distributes data across multiple databases or servers.
- Enhances write scalability and reduces the load on individual servers.
8. Database Performance Tuning:
**8.1 Indexing:
- Improves query performance by providing rapid access to specific rows.
- Balances the trade-off between read and write performance.
**8.2 Query Optimization:
- Enhances the efficiency of SQL queries through proper indexing, caching, and execution plan analysis.
- Minimizes query response time.
9. Backup and Recovery:
**9.1 Regular Backups:
- Periodic copying of the database to ensure data recovery in case of data loss or corruption.
- Includes full backups and incremental backups.
**9.2 Point-in-Time Recovery:
- Enables the restoration of the database to a specific point in time.
- Useful for recovering from system failures or human errors.
10. Database Maintenance:
**10.1 Optimization and Monitoring:
- Regular monitoring of database performance.
- Optimizing queries and indexes for improved efficiency.
**10.2 Software Updates:
- Keeping the DBMS and associated software up to date to benefit from bug fixes, security patches, and performance improvements.
Conclusion: Database architecture is a multifaceted discipline encompassing various models, patterns, and considerations. A well-designed database architecture is essential for achieving the desired balance between performance, scalability, security, and maintainability, ensuring efficient data management in diverse application scenarios.
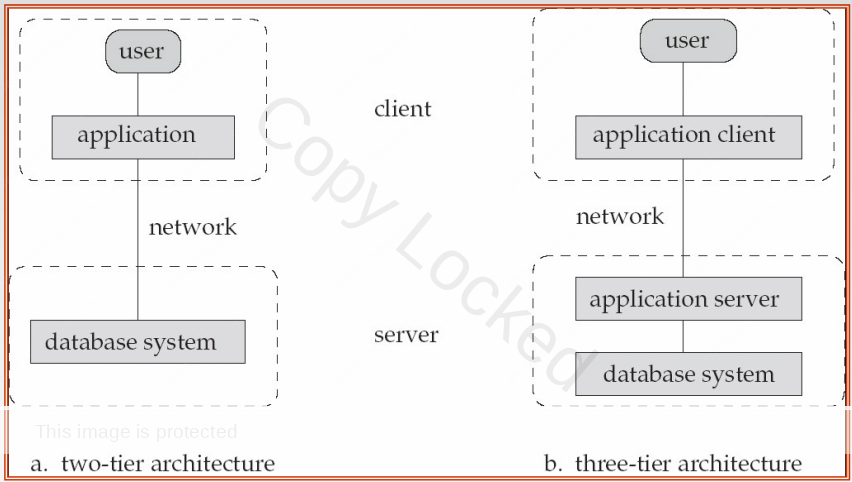
2 Tier Architecture :
Two-Tier Architecture, also known as Client-Server Architecture, is a fundamental design pattern in Database Management Systems (DBMS). This architecture divides the system into two primary components: the client and the server. Let’s delve into the details of 2-Tier Architecture:
1. Client:
1.1 Overview:
- Role: The client represents the end-user interface or application that interacts directly with the database.
- Functions:
- Provides a user-friendly interface for data entry, retrieval, and presentation.
- Captures user inputs and forwards requests to the database server.
- Processes and displays results received from the database server.
1.2 Characteristics:
- The client is responsible for managing the user interface and application logic.
- Presentation logic and user interaction are typically handled on the client side.
- Directly communicates with the database server to request and receive data.
2. Server:
2.1 Overview:
- Role: The server hosts the database management system (DBMS) and is responsible for managing and processing database operations.
- Functions:
- Executes database queries and transactions.
- Manages data storage, retrieval, and modification.
- Enforces data integrity, constraints, and security.
- Responds to requests from the client.
2.2 Characteristics:
- The server hosts the database and the DBMS software.
- Executes SQL queries and commands received from the client.
- Manages the physical storage of data and ensures data consistency.
- Directly interacts with the database to perform data-related operations.
3. Communication Flow:
Client to Server Request:
- The client sends requests to the server for data retrieval, modification, or other operations.
- Requests are typically in the form of SQL queries or commands.
Server Processing:
- The server processes the received requests by executing SQL queries against the database.
- Manages data operations, including reading, writing, updating, and deleting records.
Server to Client Response:
- The server sends the results of the executed queries or commands back to the client.
- Results may include data requested by the client or status information about the performed operations.
Client Processing:
- The client receives the results from the server.
- Processes and formats the data for presentation to the user.
User Interaction:
- The user interacts with the client interface, entering new data or initiating additional requests.
4. Advantages of 2-Tier Architecture:
- Simplicity: The architecture is straightforward with only two main components, making it relatively easy to design and implement.
- Direct Communication: The client communicates directly with the database server, minimizing communication overhead.
- Suitability: Suitable for smaller applications with a limited number of concurrent users.
5. Considerations:
- Scalability Challenges: Scaling can be challenging as both presentation and business logic are handled on the client side.
- Maintenance: Changes to the application may require updates on the client side, potentially leading to version control challenges.
- Security Concerns: Security measures need to be implemented on the client side, as direct communication with the database server exposes potential vulnerabilities.
2-Tier Architecture is well-suited for smaller applications where simplicity and direct communication between the client and the database server are more critical than scalability and extensive security measures. While it may have limitations in handling larger and more complex systems, it remains a foundational concept in database architecture.
3 Tier Architecture :
3-Tier Architecture is a design pattern for organizing the components of an application to enhance modularity, scalability, and maintainability. It separates the application into three distinct layers: the Presentation Layer (User Interface), the Application Layer (Logic and Processing), and the Data Layer (Database). Let’s explore each layer and their interactions:
1. Presentation Layer (User Interface):
1.1 User:
- Role: End-users interacting with the application.
- Functions: Provides input to the system, receives output, and interacts with the user interface.
1.2 User Application:
- Role: Manages the presentation logic and user interaction.
- Functions:
- Displays information to users through a graphical user interface (GUI).
- Captures user input and communicates it to the application layer.
- Handles user events and triggers actions based on user interactions.
2. Application Layer:
2.1 Server Application:
- Role: Encompasses the application’s business logic and processing.
- Functions:
- Processes user requests received from the presentation layer.
- Executes business logic, calculations, and workflow procedures.
- Communicates with the data layer for data retrieval or modification.
- Coordinates and manages the overall application flow.
3. Data Layer:
3.1 Server:
- Role: Hosts the Database Management System (DBMS) and the database itself.
- Functions:
- Manages data storage and retrieval operations.
- Executes database queries and transactions.
- Enforces data integrity, constraints, and security.
- Responds to requests from the server application.
Interaction Flow:
User Interaction:
- Users interact with the user interface provided by the user application.
- Input from users triggers events and actions in the user application.
User Application to Server Application:
- The user application processes user input, executes presentation logic, and sends requests to the server application.
- Requests may include data retrieval, data modification, or business logic execution.
Server Application Processing:
- The server application receives requests from the user application.
- Executes business logic and workflow procedures based on the received requests.
- Communicates with the data layer to retrieve or modify data as necessary.
Server Application to Data Layer:
- The server application interacts with the data layer to perform database operations.
- Sends SQL queries or commands to the database for data retrieval, modification, or storage.
Data Layer Processing:
- The database executes the received queries or commands.
- Manages data storage, retrieval, and modification operations.
- Enforces data integrity constraints and security measures.
Data Layer to Server Application:
- The database responds to the server application with the results of the executed operations.
- Sends back requested data or acknowledgment of completed transactions.
Server Application to User Application:
- The server application processes the results received from the data layer.
- Prepares the data for presentation and sends it back to the user application.
User Application Presentation:
- The user application receives processed data from the server application.
- Displays the information to users through the graphical user interface.
- Completes the interaction loop by presenting the outcomes of user requests.
Advantages of 3-Tier Architecture:
- Modularity: Clear separation of concerns allows for independent development and maintenance of each layer.
- Scalability: Each layer can be scaled independently, enhancing overall system scalability.
- Maintainability: Changes to one layer do not necessarily impact others, simplifying maintenance and updates.
- Security: Enhanced security due to the isolation of the data layer from direct user interactions.
Considerations:
- Complexity: While offering modularity, 3-Tier architecture may introduce complexity, particularly for smaller applications.
- Communication Overhead: Interactions between layers may introduce communication overhead, especially in distributed systems.
3-Tier architecture provides a structured and organized approach to application design, facilitating the development of robust, scalable, and maintainable systems. It has become a widely adopted model in various domains due to its ability to accommodate the complexities of modern applications.
Database Users :
In a Database Management System (DBMS), users have diverse roles and responsibilities based on their expertise and interactions with the system. Here, we focus on four distinct types of database users: Application Programmers, Sophisticated Users, Specialized Users, and Naive Users.
1. Application Programmers:
1.1 Roles:
- Design and implement applications that interact with the database.
- Write code to perform specific database operations.
- Implement business logic related to data manipulation.
1.2 Responsibilities:
- Develop software applications that utilize the database.
- Write SQL queries and statements for data retrieval and modification.
- Integrate database operations seamlessly into application code.
- Implement error handling mechanisms for database interactions.
2. Sophisticated Users:
2.1 Roles:
- Possess a strong understanding of database structures and functionalities.
- Directly interact with the database using query languages.
- Have a higher level of database knowledge compared to naive users.
2.2 Responsibilities:
- Formulate complex SQL queries for data retrieval and analysis.
- Design and execute queries to extract specific information from the database.
- Analyze query performance and optimize for efficiency.
- Participate in database tuning activities.
3. Specialized Users:
3.1 Roles:
- Have expertise in a specific domain or application area.
- Utilize the database for specialized tasks related to their field.
- May require customized access and functionalities.
3.2 Responsibilities:
- Utilize the database to extract domain-specific information.
- Define and execute queries tailored to their specialized needs.
- Collaborate with application programmers to integrate domain-specific features.
- May contribute to database design decisions in their specialized area.
4. Naive Users:
4.1 Roles:
- Have limited technical knowledge of the database system.
- Interact with the database through predefined forms and reports.
- Rely on simplified interfaces for data entry and retrieval.
4.2 Responsibilities:
- Use predefined forms for data entry and retrieval.
- Follow guided processes for interacting with the database.
- May not be involved in writing complex queries or understanding the underlying database structure.
Conclusion:
The classification of database users into Application Programmers, Sophisticated Users, Specialized Users, and Naive Users highlights the diversity of roles and responsibilities within a DBMS environment. Each user type contributes uniquely to the effective functioning of the system, ranging from developing applications and optimizing queries to utilizing the database for specialized tasks and interacting with simplified interfaces. Recognizing and understanding these user types is essential for designing user interfaces, access controls, and training programs tailored to their specific needs and expertise.
Role of a Database Administrator (DBA) :
A Database Administrator (DBA) is a crucial figure in the realm of Database Management Systems (DBMS), responsible for managing, securing, and optimizing the database environment. The role involves a diverse set of tasks to ensure the reliability, performance, and integrity of the database. Here is a comprehensive overview of the key responsibilities and functions of a DBA:
1. Database Installation and Configuration:
1.1 Installation:
Responsibility: The DBA is tasked with installing the DBMS software on servers or machines where the database will reside. This involves ensuring a smooth and error-free installation process.
1.2 Configuration:
Responsibility: DBAs configure various database parameters, settings, and options to align with organizational requirements. Proper configuration is essential for optimal performance and resource utilization.
2. Database Design and Schema Definition:
2.1 Design Oversight:
Responsibility: DBAs collaborate with system designers and developers during the design phase to ensure the creation of an efficient and effective database structure that aligns with business needs.
2.2 Schema Definition:
Responsibility: DBAs define the database schema, specifying tables, relationships, keys, and constraints. They ensure adherence to normalization principles for efficient data organization.
3. User Access Control:
3.1 User Roles and Permissions:
Responsibility: DBAs define and manage user roles and permissions, controlling access to the database to maintain data security. They follow the principle of least privilege, granting users only the necessary permissions.
3.2 Authentication and Authorization:
Responsibility: Implementing robust authentication mechanisms to verify user identities and authorization protocols to grant appropriate access levels are key responsibilities. This ensures that only authorized users access the database.
4. Performance Monitoring and Optimization:
4.1 Monitoring:
Responsibility: DBAs regularly monitor database performance using tools and system logs to identify bottlenecks, anomalies, or potential issues. Monitoring helps in proactively addressing performance issues.
4.2 Optimization:
Responsibility: Implementing optimization strategies such as index tuning, query optimization, and database caching to enhance overall system performance. DBAs work towards ensuring efficient and speedy data retrieval.
5. Backup and Recovery Management:
5.1 Backup Strategies:
Responsibility: Developing and implementing comprehensive backup strategies to safeguard data in case of system failures, corruption, or accidental deletion. Regular backups are crucial for data recovery.
5.2 Recovery Plans:
Responsibility: Creating and testing recovery plans to quickly restore the database to a consistent state after incidents or disasters. This minimizes downtime and ensures data consistency.
6. Security Measures:
6.1 Security Policies:
Responsibility: DBAs develop, implement, and enforce security policies and procedures to protect the database against unauthorized access, data breaches, and malicious activities.
6.2 Security Audits:
Responsibility: Conducting regular security audits, vulnerability assessments, and penetration testing to identify and mitigate potential security risks and vulnerabilities.
The role of a Database Administrator is dynamic and critical to the smooth functioning of an organization’s information systems. DBAs serve as custodians, ensuring that databases operate efficiently, securely, and reliably throughout their lifecycle. They play a pivotal role in maintaining data integrity, optimizing performance, and upholding security standards within the database environment.